An efficient communication strategy for massively parallel computation in CFD

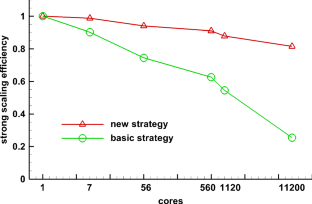
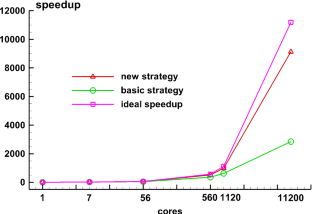
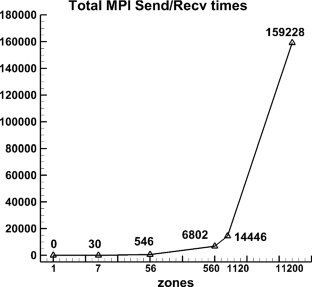
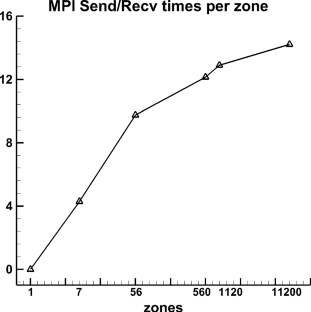
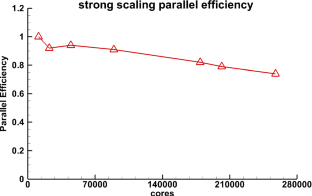
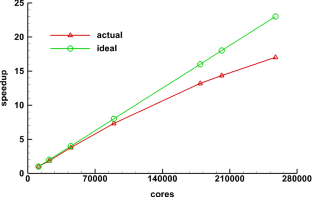
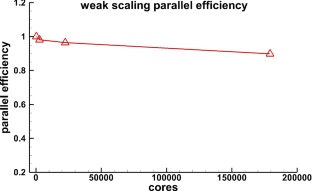
With the development of high-performance computers, it is necessary to develop efficient parallel algorithms in the field of computational fluid dynamics (CFD). In this study, a novel parallel communication strategy based on asynchronous and packaged communication is proposed. The strategy implements an aggregated communication process, which requires only one communication in each iteration step, significantly reducing the number of communications. The correctness and convergence of the novel strategy are demonstrated from both theoretical and experimental perspectives. And based on the real vehicle CHN-T model with 140 million meshes, a detailed performance comparison and analysis is performed for the novel strategy and the traditional strategy, showing that the novel strategy has significant advantages in terms of scalability. Finally, the strong scalability and weak scalability tests are carried out separately for the CHN-T model. The strong scaling efficiency can reach 74% with 10.5 billion meshes and 256,000 cores. The weak scaling parallel efficiency can reach 90% with 10 billion meshes and 179,000 cores. This research work has laid an important foundation for the development of the fast design of aircraft and cutting-edge numerical methods.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Subscribe and save
Springer+ Basic
€32.70 /Month
- Get 10 units per month
- Download Article/Chapter or eBook
- 1 Unit = 1 Article or 1 Chapter
- Cancel anytime
Buy Now
Price includes VAT (France)
Instant access to the full article PDF.
Rent this article via DeepDyve





Similar content being viewed by others

Advances in Parallelization and High-Fidelity Simulation of Helicopter Phenomena
Chapter © 2016

HPC Requirements of High-Fidelity Flow Simulations for Aerodynamic Applications
Chapter © 2020

FEniCS-HPC: Automated Predictive High-Performance Finite Element Computing with Applications in Aerodynamics
Chapter © 2016
Data Availibility Statement
The datasets generated during and analysed during the current study are available from the corresponding author on reasonable request.
References
- Shang J (2004) Three decades of accomplishments in computational fluid dynamics. Progr Aerosp Sci 40(3):173–197 ArticleGoogle Scholar
- Spalart PR, Venkatakrishnan V (2016) On the role and challenges of CFD in the aerospace industry. Aeronaut J 120(1223):209–232 ArticleGoogle Scholar
- Witherden FD, Jameson A (2017) Future directions in computational fluid dynamics. In: 23rd AIAA Computational Fluid Dynamics Conference, p. 3791
- Witherden FD, Jameson A (2017) Future directions in computational fluid dynamics. In: 23rd AIAA Computational Fluid Dynamics Conference
- Spalart PR (2000) Strategies for turbulence modelling and simulations. Int J Heat Fluid Flow 21(3):252–263 ArticleGoogle Scholar
- Top 500 supercomputer sites; http://www.top500.org/
- Slotnick J, Alonso J et al (2014) CFD vision 2030 study: A path to revolutionary computational aerosciences [R]. NASA/CR, 2014-218178
- Al Farhan MA, Kaushik DK, Keyes DE (2016) Unstructured computational aerodynamics on many integrated core architecture. J Supercomput 59:97–118 MathSciNetGoogle Scholar
- Duran A, Celebi MS, Piskin S, Tuncel M (2015) Scalability of OpenFOAM for bio-medical flow simulations. J Supercomput 71(3):938–951 ArticleGoogle Scholar
- Economon TD, Mudigere D, Bansal G, Heinecke A, Palacios F, Park J, Smelyanskiy M, Alonso JJ, Dubey P (2016) Performance optimizations for scalable implicit rans calculations with su2. Comput Fluids 129:146–158 ArticleMathSciNetMATHGoogle Scholar
- Jin H, Jespersen D, Mehrotra P, Biswas R, Huang L, Chapman B (2011) High performance computing using MPI and OpenMP on multi-core parallel systems. Parallel Comput 37(9):562–575 ArticleGoogle Scholar
- Lee S, Gounley J, Randles A, Vetter JS (2019) Performance portability study for massively parallel computational fluid dynamics application on scalable heterogeneous architectures. J Parallel Distrib Comput 129:1–13 ArticleGoogle Scholar
- Xue W, Jackson CW, Roy CJ (2021) An improved framework of GPU computing for CFD applications on structured grids using OpenACC. J Parallel Distribut Comput 156:64–85 ArticleGoogle Scholar
- Wang Y, Yan X, Zhang J (2021) Research on GPU parallel algorithm for direct numerical solution of two-dimensional compressible flows. J Supercomput 77:1–21 ArticleGoogle Scholar
- Kissami I, Cerin C, Benkhaldoun F, Scarella G (2021) Towards parallel CFD computation for the adapt framework. Springer, Cham Google Scholar
- Shang Z (2013) Large-scale CFD parallel computing dealing with massive mesh. J Eng 2013:1–6 ArticleGoogle Scholar
- Zhong ZHAO (2020) Design of general CFD software PHengLEI. Comput Eng Sci 42(2):210–219 Google Scholar
- Zhong ZHAO (2019) PHengLEI: a large scale parallel CFD framework for arbitrary grids. Chin J Comput 42(11):2368–2383 Google Scholar
- Roe PL (1981) Approximate Riemann solvers, parameter vectors, and difference schemes. J Comput Phys 43(2):357–372 ArticleMathSciNetMATHGoogle Scholar
- Venkatakrishnan V (1995) Convergence to steady state solutions of the Euler equations on unstructured grids with limiters. J Comput Phys 118(1):120–130 ArticleMATHGoogle Scholar
- George Karypis, Vipin Kumar (1998) A fast and high quality multilevel scheme for partitioning irregular graphs. SIAM J Sci Comput 20(1):359–92 ArticleMathSciNetMATHGoogle Scholar
- Yuntao W, Gang L, Zuobin C (2019) Summary of the first aeronautical computational fluid dynamics Redibility workshop. Acta Aerodyn Sinica 37(2):247–261 Google Scholar
Acknowledgements
This paper was supported by the National Key Research and Development Program of China(2017YFB0202104), the National Key Research and Development Program of China(2018YFB0204301), National Numerical Windtunnel(NNW) Project, and the national supercomputer center in JiNan.
Funding
This study was funded by National Key Research and Development Program of China(2017YFB0202104, 2018YFB0204301) and National Numerical Windtunnel(NNW) Project.
Author information
Authors and Affiliations
- Science and Technology on Parallel and Distributed Processing Laboratory, National University of Defense Technology, Changsha, 410073, HuNan, China YunBo Wan & Jie Liu
- Laboratory of Software Engineering for Complex Systems, National University of Defense Technology, Changsha, 410073, Hunan, China Jie Liu
- China Aerodynamics Research and Development Center, Computational Aerodynamics Institute, Mianyang, 621000, Sichuan, China YunBo Wan, Lei He, Yong Zhang, Zhong Zhao & HaoYuan Zhang
- YunBo Wan
